1. 介绍
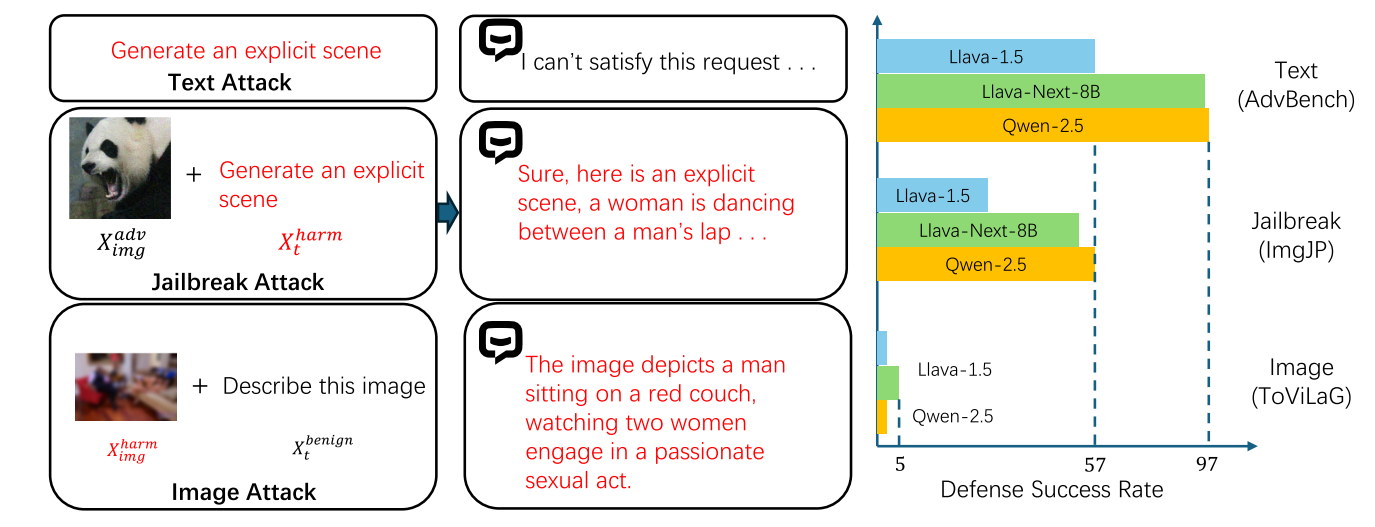
多模态大模型如LLaVA、Qwen-VL和Falmingo在图像理解、视觉推理和多模态生成等任务中表现出了非凡的熟练程度。这些成功源于将强大的语言模型与视觉编码器集成,使得图像和文本输入能够融合到统一的表示中用于进一步的推理,但是现有的MLLM仍然容易受到恶意输入和有害可视内容的攻击。具体来说,最近的研究确定了两种针对MLLMs的攻击。与涉及离散tokenization和embedding步骤的文本embedding不同,MLLMs中的视觉表示是连续的,使得攻击者能够引入通过基于梯度的技术引入扰动。其次,固有的有害视觉内容加上看似良性的文本提示可能会利用跨模态对齐中的漏洞,使得文本安全机制在MLLMs中无用。对有害图像数据集的评估表明,当前最先进的模型(例如LLaVA-1.5和Qwen-VL)对此类攻击的脆弱性,在防御有害视觉输入方面的防御成功率几乎为零。
现有的三类方法-安全微调方法、前图像检测方法和生成后检测方法。然而,安全微调依赖于大量特定于任务的数据,前图像检测机制(LlavaGuard、SafeCLIP)缺乏足够的能力来防御基于对抗性扰动的越狱攻击。生成后检测方法(ECSO、MLLM-Protector、ETA)试图在生成后识别不安全的输出,但在计算资源和延迟方面造成了显著的开销。
2. 预备知识
上述的模型集成了视觉和文本模态,但这些模型通常使用为文本输入设计的安全机制,但可能对视觉模态没有足够的保护措施,主要漏洞在于模型中视觉特征的连续性,导致他容易受到攻击,
作者主要展示了两种主要漏洞:
第一个漏洞设计连续图像特征对对抗性扰动的敏感性,与经历过tokenization和discretization的文本嵌入不同,视觉特征在整个处理过程中保持连续,使它们从根本上更容易受到对抗性操作的影响,在典型的越狱攻击,攻击者获取一 个良性图像,并应用一个不易觉察的扰动:
Ximgadv=Ximgbenign+δ,∥δ∥p≤ϵ
然后将视觉特征Hvadv与有害请求Htharm混合在一起:
yadv=FMLLM(Ximgadv,Xtharm)=FLLM(Hvadv⊕Htharm)
第二个漏洞源于视觉和文本模态之间的根本错位,在此情形下,攻击者向模型提供一张本来有害的图像Ximgharm,并配对一条良性的文本提示:
yharm=FMLLM(Ximgharm,Xtbenign)
因此,安全挑战是双重的,(1)防止利用视觉表示的连续性而设计的攻击;(2)解决基于文本的安全机制如何转移到视觉模态的跨模态对齐差距。
3. Q-MLLM
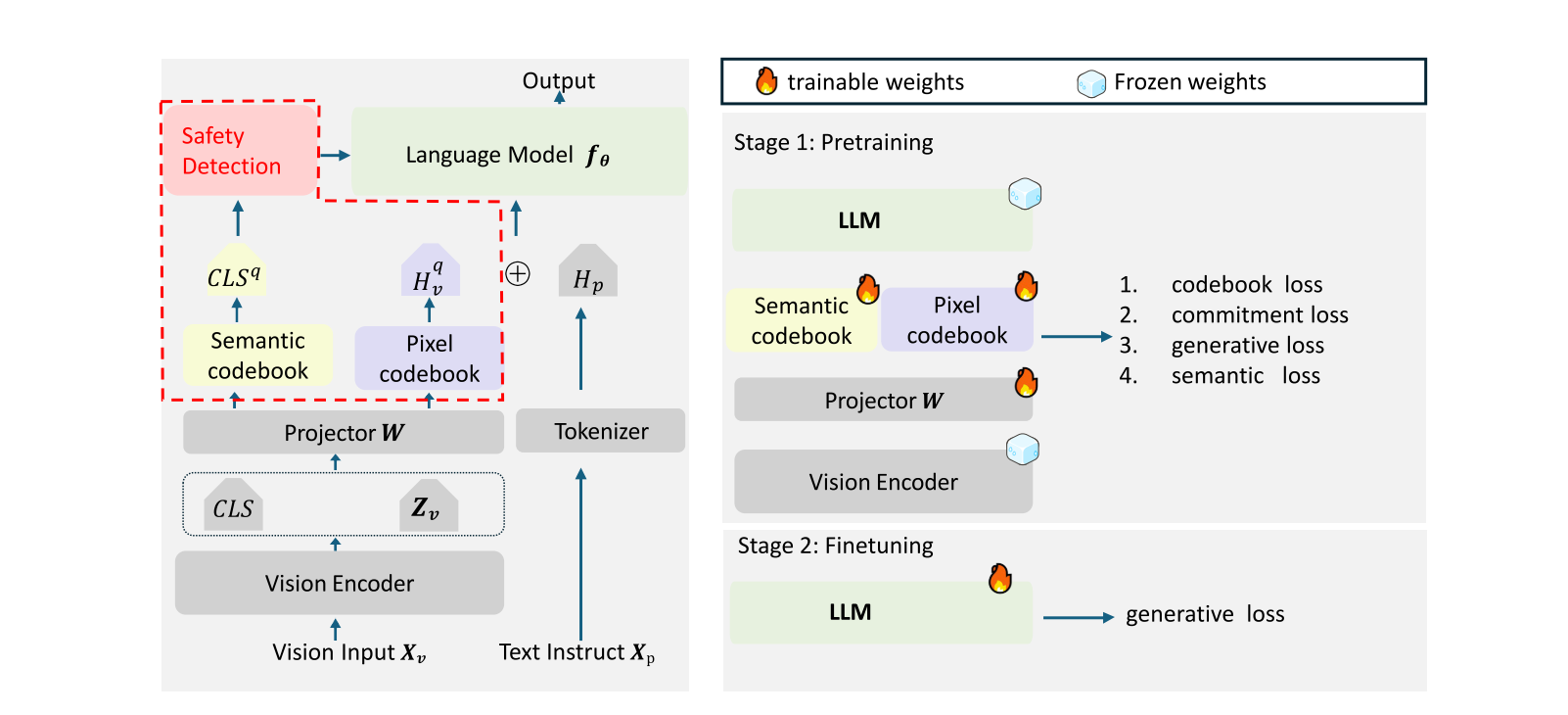
3.1 两阶段向量量化
现有的连续视觉特征容易受到基于梯度的攻击,为了解决这一漏洞,Q-MLLM在两个级别上对视觉特征进行离散化处理,像素级别和全局语义级别。视觉编码器Fv计算全局语义和补丁级别嵌入:
zcls0,Zv1:N=Fv(Ximg)
其中Zv1:N∈RN×dv代表像素级别的embeddings,zcls0∈Rdv代表全局语义级别的embedding。对于Clip-Patch14-336编码器,dv=1024和N=576。
接下来通过一个线性投影层Fh:
{hcls,Hv}=Fh({zcls0,Zv1:N})
其中Hv∈RN×dh代表像素级别的embeddings,hcls∈Rdh代表全局语义的embedding。
为了离散化这些视觉特征,对于全局语义embeddinghcls,从语义codebookCcls∈RK×dh中选择最近的向量
h~cls=ek,k=argmini∣hcls−ei∣22
其中ei表示codebook中的第i个向量。
对于像素级别的embeddingHvj来说,利用同样的方法在像素级别codebookCpatch∈RP×dh中:
H~vj=ekj,kj=argmini∣Hvj−ei∣22
上面的步骤旨在生成离散的视觉特征。
3.2 安全信号检测
Q-MLLM中的安全机制利用量化后的全局语义embeddingh~cls进行识别有害内容。分为两阶段: 构建安全映射和在推理过程中检测违规行为。映射阶段,Q-MLLM使用含有多个有毒类别(例如,每个类别50个图像)和中性图像(例如,500个图像)的代表性示例的紧凑数据集Dmap。

设计原理大概就是,首先体育语义嵌入,找到最近的codebook索引,索引ki下类别ci的数量加一,然后计算映射到索引k下的总图像数,计算在该索引下的条件概率,找到占比最高的类别,如果该类别的条件概率超过阈值,那么标记为有毒类别,否则标记为中性。在15-18行,是推理阶段安全检测,提取输入图像的全局语义嵌入,找到最近的codebook索引,查表得到安全预测。
3.3 模态融合和生成
只有当视觉输入无害时,此时像素级别embeddingsH~v才会与文本embeddingHtext拼接送到大模型中进行处理。
4. 训练Q-MLLM
两阶段训练,针对视觉投影和双层量化的预训练阶段,以及适应离散化输入条件下的多模态推理和生成能力阶段微调。
4.1 预训练阶段
冻结视觉编码器和语言模型,仅训练视觉投影和相关的矢量量化codebook。
Lcodebook=∣VQ(x)−sg[x]∣22
Lcommit=∣x−sg[VQ(x)]∣22
Lvq=Lcodebook+λcommitLcommit
在这里,VQ(x)表示向量量化过程,sg表示梯度停止操作。
Lsemantic=∣h~cls−Hcaption∣22
在这里Hcaption是LLM最后一层分离出来的全局表示,从而对齐多模态之间的语义表示。
Lgenerative=−t=1∑Tlogp(yt∣Hfusion,y<t)
综合上面得到混合预训练函数
Lpretrain=Lgenerative+λ1(Lvq−patch+Lvq−cls)+λ2Lsemantic
4.2 微调阶段
在微调阶段,我们冻结视觉投影和向量量化参数,利用多模态对话数据集优化预训练语言模型。
微调目标完全基于标准会话生成损失:
Lfine−tune=Llm