论文总结:SemiSAM+:Rethinking semi-supervised medical image segmentation in the era of foundation models
3. 方法
3.1 预备知识
给定一个带有个示例的,和个未标注示例的,其中和分别代表已标注和未标注的输入图像,代表已标注数据的标签。通常,是一个数据集相对较小的子集,这意味着。对于半监督分割模型来说,我们的目标是利用标注数据和未标注数据进行学习,使得其性能与在全监督模型的性能相当。
与生成伪标签和迭代更新分割模型不同,半监督医学图像分割的最新进展是利用无监督正则化将未标记数据纳入训练过程。
下图提出了所提出的SemiSAM+框架,该框架由两部分组成:(1)可训练的任务专用分割模型(专家模型),用于下游分割任务;(2)一个或多个可提示的通才模型,这些模型具有zero-shot泛化能力。在现有框架基础上,SemiSAM引入置信度感知正则化机制,通过有效利用通才模型的监督信号来避免潜在误导,同时辅助专家模型实现高效标注学习。
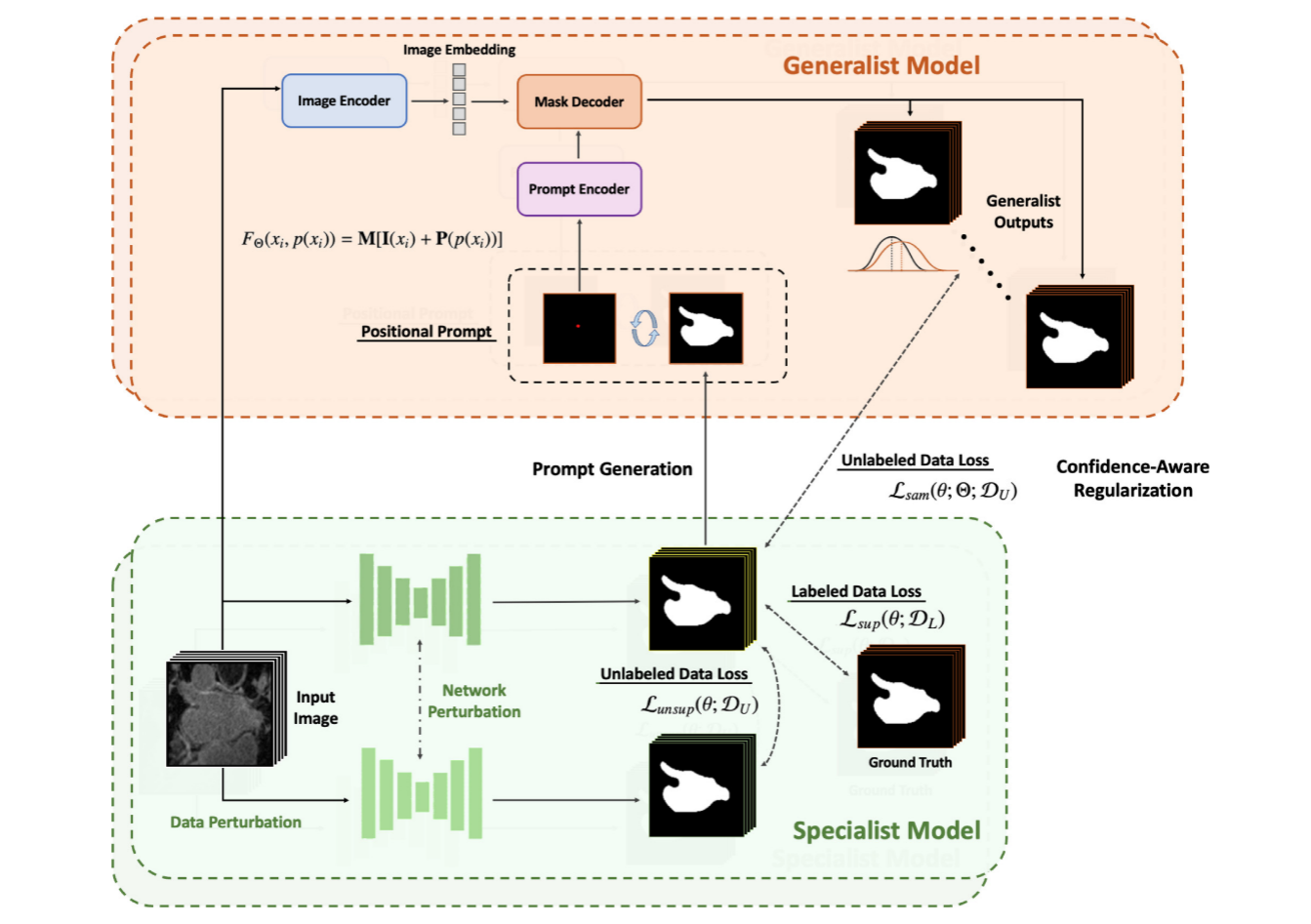
3.2 Specialist Model
对于有标注数据集,我们计算主分割输出与真实标签之间的监督分割损失。而对于未标注数据集,则通过计算无监督正则化损失来挖掘图像内部信息。不同的半监督分割框架主要通过差异化策略生成无监督正则化损失以利用未标注数据进行训练。传统半监督学习框架中专家模型的优化总损失可表述如下:
在这篇文章中,作者使用了四个具有代表性的SSL框架。我们在后面将详细讨论。
3.3 Generalist Model
SAM采用图像编码器提取图像嵌入,提示编码器通过不同的提示模式整合用户交互,掩码解码器通过融合图像嵌入和提示嵌入来预测分割掩码。在本工作中,我们使用SAM-Med3D作为以下实验中的默认Generalist Model。
3.4 SemiSAM+
如上图框架所示,SemiSAM+的训练过程包括specialist-generalist协同学习,在这里可训练的specialist为冻结的generalist提供位置提示已获得伪分割,然后generalist的输出为specialist提供监督信号。在通用可提示分割中,分割结果主要依赖于输入的提示,不同于人工提示的分割模式,SemiSAM+利用specialist的分割输出为generalist生成提示。景观初始分割效果欠佳,但其输出足以实现目标粗定位。作者在文章中使用了多种提示策略:粗分割结果作为掩码提示,基于粗分割生成点提示。
对于SAM的提示分割流程可表示为:
其中分别表示图像编码器,提示编码器和掩码解码器,表示输入图像的位置提示。
可训练的Specialist的分割结果为generalist生成位置提示,位置提示获取可表示为:
当存在大量标注数据时,单纯强制specialist与generalist输出一致性的改进效果有限。在SemiSAM+中,通过不同提示近似分割不确定性。generalist的偶然不确定性表述如下:
其中通过计算不同输入提示下预测结果的统计差异来估计不确定性。然后按照如下方式组织置信度感知正则化:
最终训练损失为:
3.5 扩展多generalist模型
给定个generalist,参数分别为,训练损失可以扩展为: