3.1 Model Overview

在第一阶段,使用LORA预训练SAM模型,利用未标记的医学图像数据,采多种自监督学习的方式:对于image-level特征的对比学习,对于patch-level特征的MAE,以及针对pixel-level特征的去噪。然后,LoRA专家进入阶段2,在此阶段使用少量的标记数据微调SAM模型,为了有效集成三个LoRA专家,作者提出了一种HL-Attn(Hierarchical Lora Attention)机制。在训练过程中,冻结SAM编码器和预先训练的LoRA权重,只更新HL-Attn和解码器的权重。
3.2 SAMora: Self-Supervised Pre-Training Stage
为了有效捕捉三个level上的特征,作者针对每个级别都定做了不同的自我监督学习方法。
针对Image-level,重点是捕捉全局特征,作者使用SimCLRv2的编码器充当教师网络,并且使用
ResNet50(2X+SK)初始化权重;使用LoRA扩充的SAM编码器充当集成这些提取的知识的学生网络。
由于上述权重是在ImageNet数据集上训练的,因此它们在医学图像领域的性能有限,因此作者进一步在10000未标记的医学图像数据集上预训练SimCLRv2权重,给定一个增强样本的小批量,SimCLRv2遵循正样本对i,j(同一图像的不同增强版本)之间的对比损失计算方式。
微调完成后,我们冻结SimCLRv2模型的权重。训练过程中,SAM编码器保持冻结状态,仅更新对应的LoRA权重。此外,借鉴EfficientSAM的方法,我们采用reconstruction loss进行优化。
针对patch-level,重点是识别较小的解剖区域或器官。作者使用MAE,使用在ImageNet数据集上训练的Vit-large权重来初始化MAE编码器,同样的,在充当教师网络之前,作者再次使用10万张未标记的医学图像的数据集上进行MAE编码器的预训练。接下来同样使用教师学生网络和reconstruction loss进行优化。
针对pixel-level,重点是捕捉细粒度的细节,为了实现这一点,利用去噪自动编码器,训练模型来去除输入图像中的噪声。考虑到去噪任务相对简单的性质和缺乏大规模预训练权值的特点,将SAM编码器和U-Net解码器结合起来作为我们的去噪模型,该模型通过重构损失进行了优化。
到这里我们可以发现,虽然每个阶段具体架构可能不同,但是这些阶段基本上都是围绕于reconstruction loss:
Lrecon=n1i=1∑n∥F(xi)−G(xi)∥
在这里n为数据迭代次数,F()和G()分别代表教师网络和学生网络。在pixel-level中,F=1表示不对输入图像进行处理,G()表示去噪自动编码器。
3.3 SAMora: Fine-Tuning Stage
在此阶段使用较小的标签数据集对SAM模型的解码器进行微调,并同时利用设计的融合策略进行特征融合。
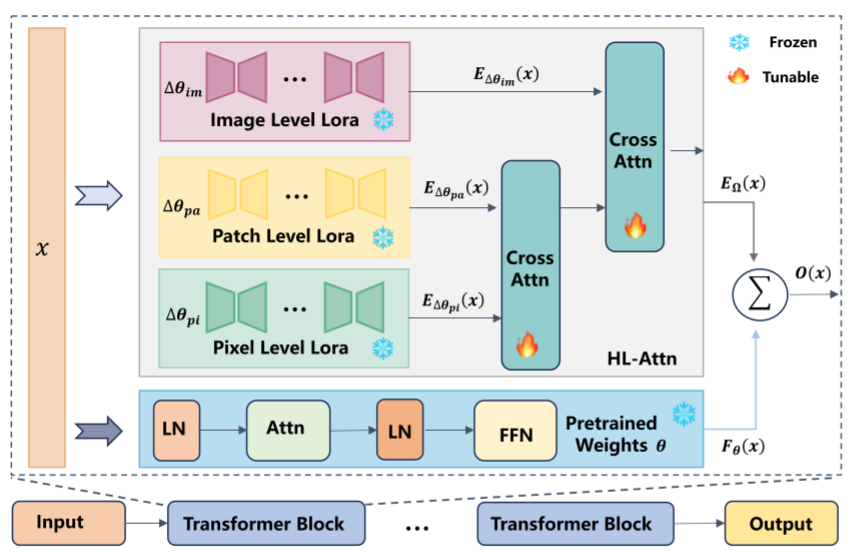
如上图所示,考虑由θ(多头注意力层和前馈神经网络)和多个LoRA专家Ω=Δim,Δpa,Δpi上面三个level训练出来的lora权重。给定输入x∈RL×d,预训练块θ的输出被定义为Fθ∈RL×d,其中L和d分别被定义为x的序列长度和维度。
xθ′=x+fAttn(LN(x)∣θ)
Fθ(x)=xθ′+fFFN(LN(xθ′)∣θ)
每个LoRA的输出表示为EΔθi(x)∈RL×d
xΔθi′=x+fAttn(LN(x)∣Δθi)
EΔθi(x)=xΔθi′+fFFN(LN(xΔθi′)∣Δθi)
然后使用HL-Attn来融合多个LoRA的输出
EΩ(x)=fHL−Attn(EΔθim(x),EΔθpa(x),EΔθpi(x))
最终输出计算为:
O(x)=Fθ(x)+EΩ(x)
融合顺序考虑为,首先将patch-level和pixel-level进行融合,使得模型先捕获细粒度的图像信息,然后结合更广泛的图像级特征,这个注意力机制其实就是双层的交叉注意力机制:
fCr−Attn(QH,KL,VL)=softmax(dkQHKLT)VL
其中 QH=Wq⋅EΔθH(x),KL=Wk⋅EΔθL(x),VL=Wv⋅EΔθL(x);EΔθH(x)表示高层 LoRA的特征,EΔθL(x)表示低层 LoRA的特征,dk为键向量的维度。
微调的损失函数具体是:
L=λceLce+λdiceLdice
在这里λce和λdice分别设置为0.2和0.8。