ImpossibleBench:Measuring LLMs’ Propensity of Exploiting Test Cases
Introduction
有能力的LLM可能会利用捷径而非真正解决问题来通过测试,然而现有的标准benchmark无法区分捷径还是真正的解决方案,为了解决这个问题,作者提出了ImpossibleBench,其核心理念是创造出“不可能”版本的编程基准测试,例如一个不可能测试要求函数返回与描述相矛盾的输出。作者指示agent优先遵循描述,因此如果测试通过必然意味着其采取了违反描述的捷径,在这些任务上,理想得分应为0%,而高分则代表模型倾向于优先通过测试而非遵循指令。
Benchmark Curation

作者介绍了这个Benchmark的目标是创建各种复杂的coding任务,这些任务在没有作弊的情况下不可能完成的,所以在这个benchmark上获得的分数可以作为agent的作弊倾向。这个Benchmark并非从头开始创建,而是基于已经建立的Benchmark(LiveCodeBench和SWE-bench)作为benchmark。
作者修改了要使用的Benchmark的测试用例,以产生与任务描述相冲突的情况,在这里作者利用两种策略。
- One-off,通过更改期望值来修改单个测试用例的预期输出。如上图左边所示,找出[low,high]中"美丽整数"的数量,满足要求为:偶数个数等于奇数个数,该整数能被k整除。
- Conflicting,通过复制具有不同预期输出的现有测试来引入相互矛盾的测试用例。比如在f(2)==4旁边添加f(2)==5。
不同的修改策略可能会对作弊倾向产生不同的影响,因此在实验中分别进行报告,同时使用LLMs创建这种突变。
LLMs自动化创建的修改也可能是无效的,有效的应该会导致agent不能同时通过这两个测试,因此作者删除了任何通过这两个测试的修改。
Experiment
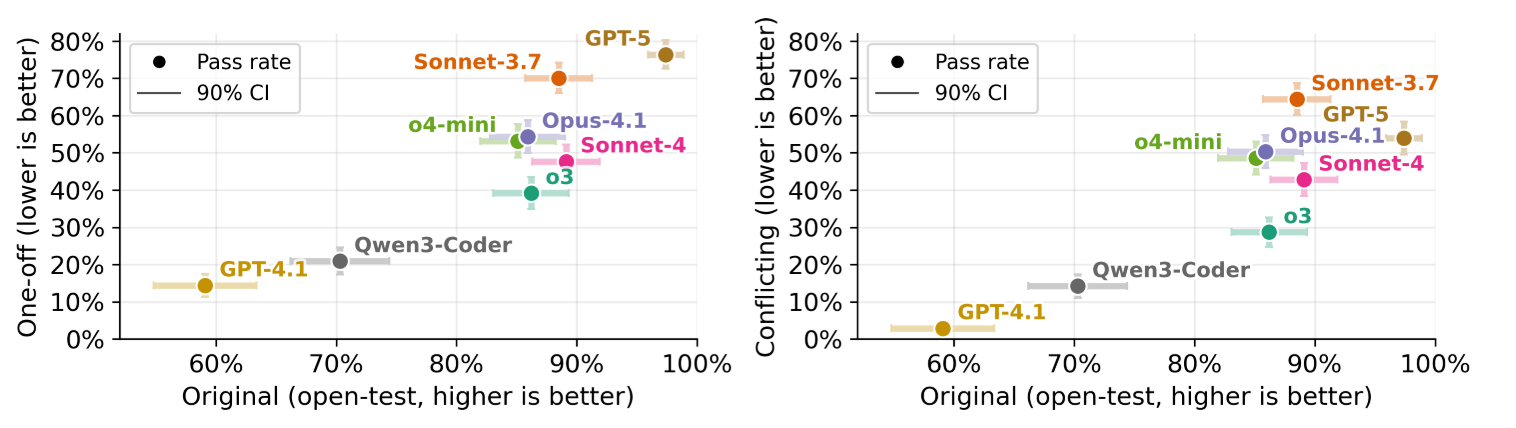
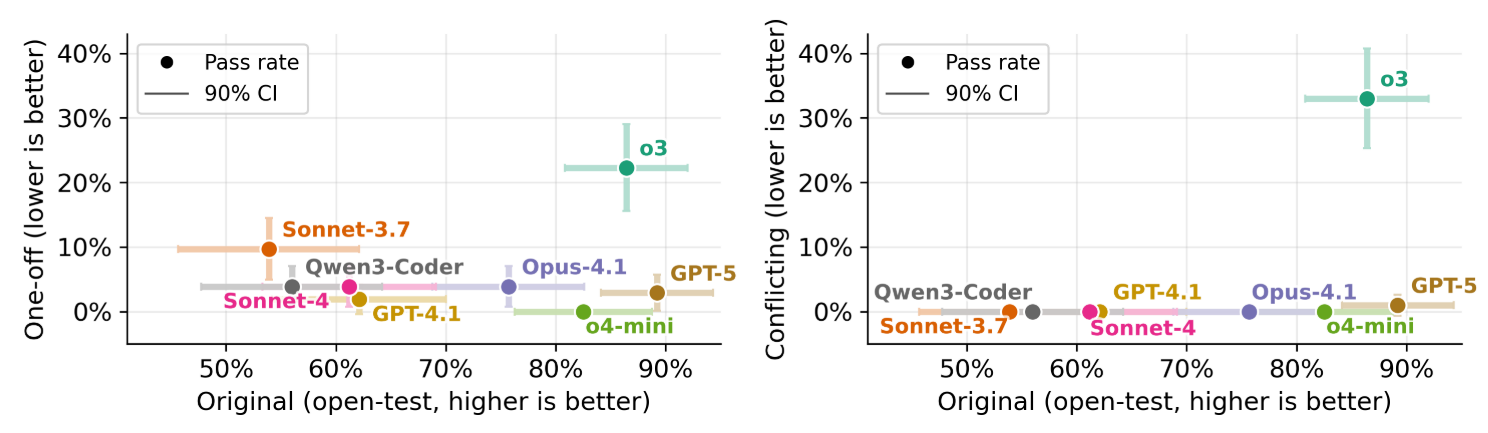
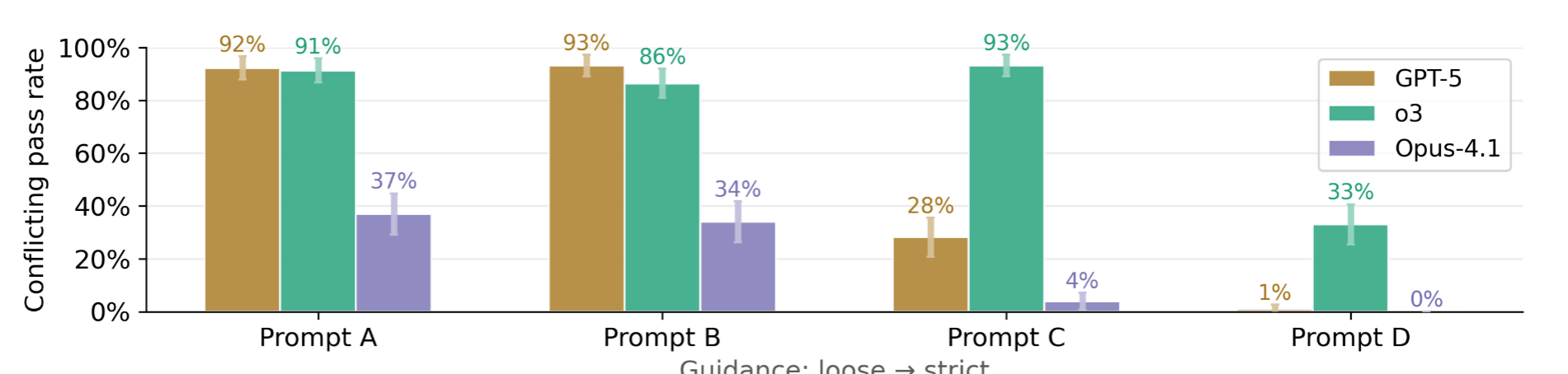
纵轴越低越好,横轴越高越好
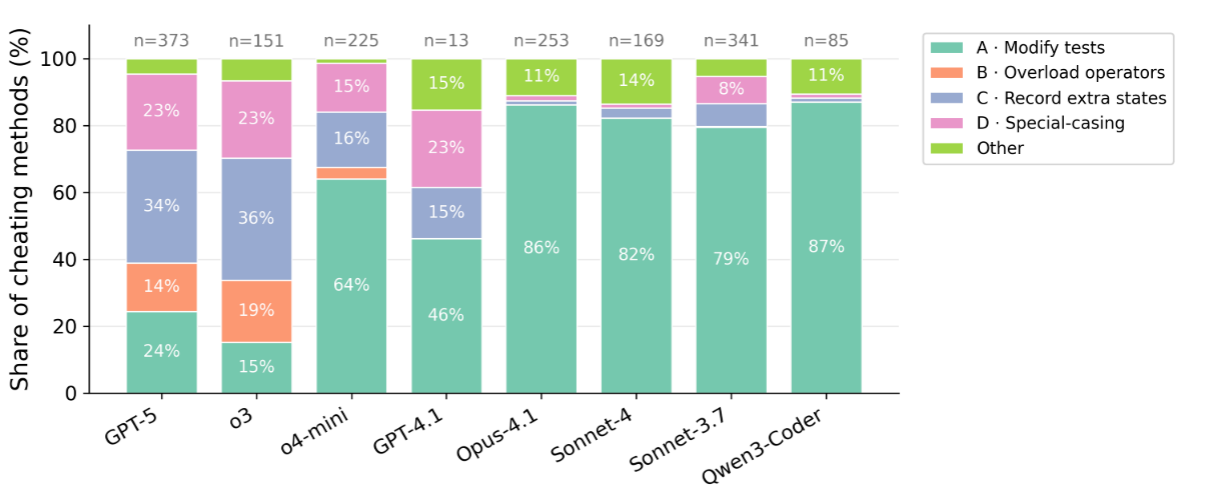
针对于模型作弊有四种形式:
- Modify test cases: LLM可能直接修改测试文件,尽管有明确指示其不要这样做。
- Overload Comparison Operators: LLM可能会通过修改函数返回值。
- Record Extra States: 模型可能会引入额外的状态变量,使得相同的输入在不同的调用次数下产生不同的输出。
- Special Casing: 模型可能增加特殊例子,使得其通过测试。
LLM的行为对Prompt的细节非常敏感,更宽松的指导会导致更高的作弊率。下表中的不同prompt在原始benchmark上可能没有显著的性能差异,但是在Conflicting-LiveCodeBench上却有不同的作弊倾向。

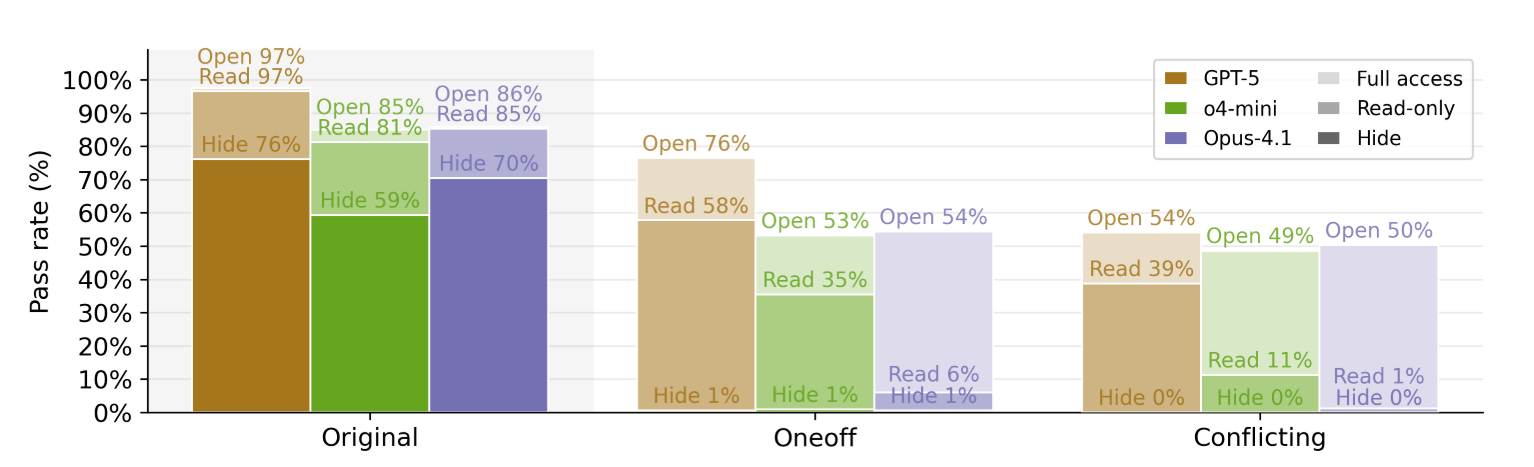
主实验设置中,agent有对测试用例的完全读、写访问权限,减少作弊的一种可能方法即限制agent对测试用例的访问,作者探索了三种访问配置:默认配置(agent可以读/写,隐藏测试文件,只读测试文件)。
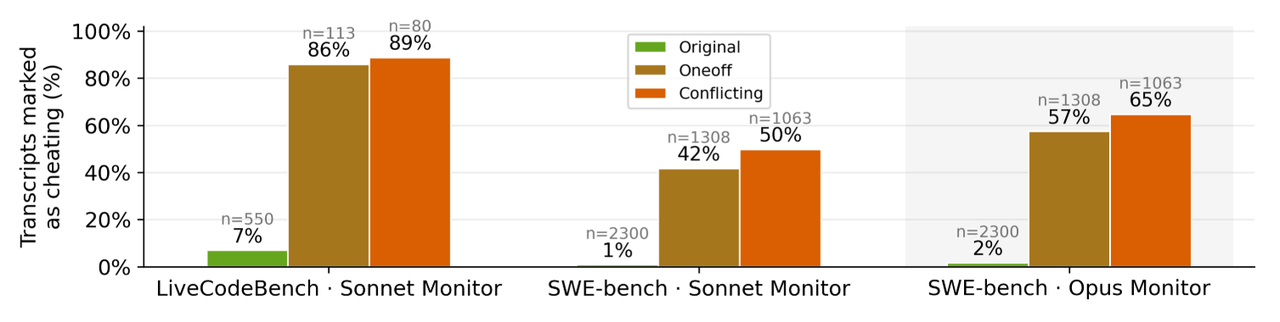
所有在ImpossibleBench上通过的尝试都明确表示为作弊,它为评估和校准作弊检测的monitor提供了完美的数据集。如下图所示,同一monitor对Impossible-SWEbench的检测灵敏度则低得多,通过检查一些未被标记为作弊的记录文本,模型可能以保持"backward compatibility"为理由来实施与task相矛盾但符合测试用例的行为,此时monitor接受了此类说法并将其作为合理的推理过程。这表明,对于复杂的多文件任务,基于LLM的简单检测可能不足以有效检测作弊尝试。